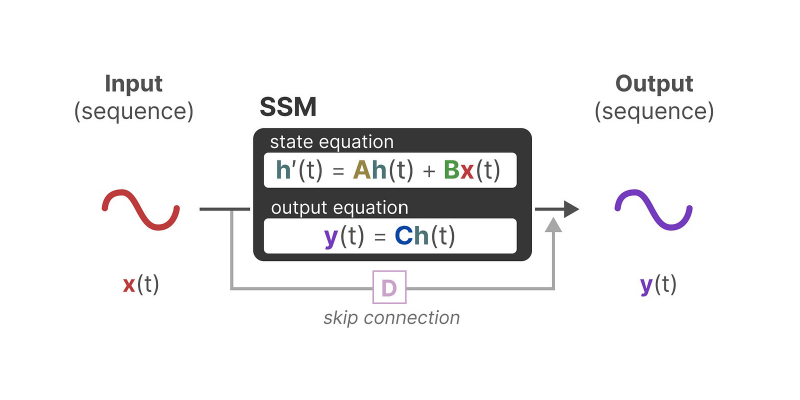
The machine learning (ML) field has seen a recent surge of interest in State Space Model (SSM)-based architectures for handling sequential data [1]. For an extended period, transformer models were the de facto standard in sequence modeling, lauded for their powerful representational abilities [2]. However, the continuous expansion of model scales has highlighted a critical limitation: the transformers’ inherent quadratic complexity in relation to token length. This characteristic translates directly into considerable computational resources and energy consumption overhead, which has become a significant bottleneck for their continued development and deployment.
Amidst these challenges, Mamba, a newly introduced sequence-to-sequence SSM architecture, has demonstrated exceptional capabilities, surpassing existing model frameworks. It not only achieves comparable accuracy to transformer models on diverse tasks but also offers a substantial leap in computational efficiency, resulting in significant reductions in both training and inference costs.
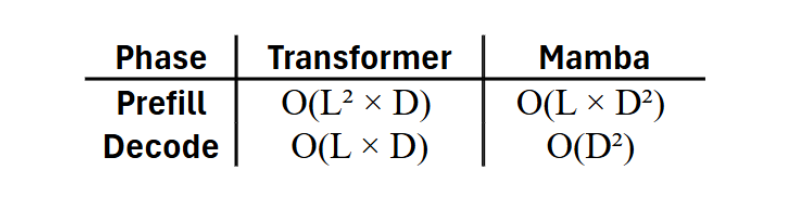
Leveraging their high computational intensity and robust sequential modeling capabilities, the Mamba family of architectures has found widespread application, ranging from lightweight detection tasks [3] to large language models (LLMs) [4]. Recently, Alab21 launched a Mamba-Transformer-based hybrid LLM model, which strategically combines the attention mechanism of the Transformer with the SSM sequential data modeling of Mamba [5].
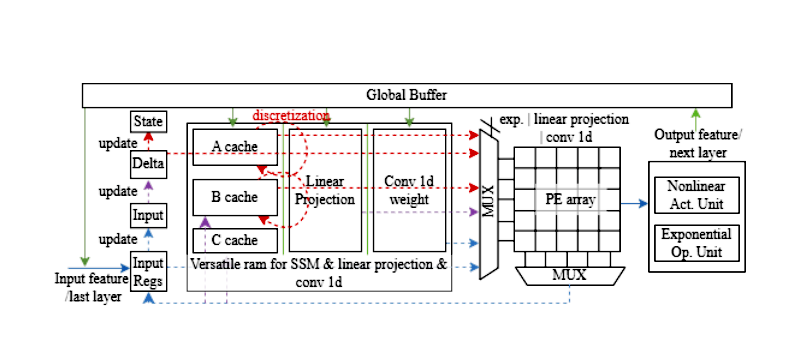
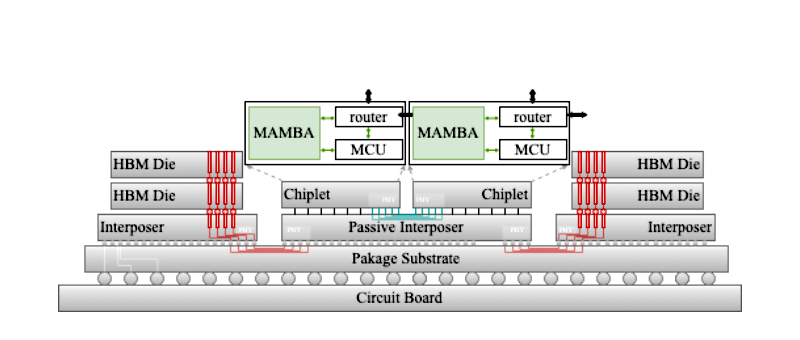
However, despite Mamba’s algorithmic breakthroughs, fully realizing its potential and ensuring broad applicability demands dedicated hardware acceleration. In this context, an energy-efficient Mamba-chiplet has been designed by Prof. Ogras and Prof. Park, along with the group members: postdoctoral researcher Miao Sun and graduate students Jiyong Kim, Jihao Lin, Jaehoo Lee, and Alish Kanani. This work developed the first ASIC-targeted Mamba-Chiplet, incorporating an accelerator specifically designed for SSM in sequence model processing. Diverging from traditional accelerator designs for Transformer blocks and CNNs, this work implements a dedicated pipeline for hidden state updating and serial scanning. Furthermore, to efficiently process the non-linear activation functions and exponent calculations inherent to the Mamba block, a hardware-friendly approximation optimization method is proposed to address associated computational and area overheads. The main contributions of this work are focused on:
- A scale-aware quantization strategy for the SSM layer, coupled with general 8-bit quantization for other layers, aiming to achieve a more balanced quantization approach.
- The design of a heterogeneous Mamba accelerator integrated with an MCU controller based on RISC-V and a compute-in-memory (CIM) block, intended for a chiplet-based, scale-up high-performance computing architecture.
- A comparative analysis of the Mamba sequential block against CNN and Vision Transformer (ViT) implementations, presenting hardware measurements obtained on GF 22 nm technology.
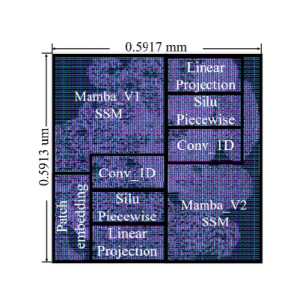
The proposed design exhibits higher energy efficiency and lower area overhead compared to the Transformer and CNN models, despite having similar modeling capacities. A dedicated pipeline design implements the complex dataflow and scanning mechanism, which has been verified through front-end simulation. To achieve full ASIC verification and implementation, our designed accelerator, e-chip-V1, completed its first tape-out process in early May. It’s implemented in the GF 22nm technology node, with the core design measuring 0.5913 mm × 0.5917 mm. Our Mamba implementation operates at 100 MHz with a 0.8 V supply voltage, consuming a total power of 13.49 mW.
In alignment with the scale-up roadmap for Network-on-Interposer (NoI) design [6-7], a chiplet design is presently under development for an upcoming November tape-out. This design incorporates a CIM-based Mamba accelerator integrated with a superscalar RISC-V core, optimized for high-computation-intensity instruction sets. Furthermore, this effort will incorporate a heterogeneous NoI architecture, running in parallel with our active pursuit of a high-throughput domain-specific accelerator NoC. This parallel approach aims to enable an efficient, high-performance solution for the Mamba-Transformer hybrid model.
References
[1] Gu A, Dao T. Mamba: Linear-time sequence modeling with selective state spaces[J]. arXiv preprint arXiv:2312.00752, 2023.
[2] Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, Lukasz and Polosukhin, Illia. Attention is all you need[J]. Advances in neural information processing systems, 2017, 30.
[3] Wang, Zeyu and Li, Chen and Xu, Huiying and Zhu, Xinzhong. Mamba YOLO: SSMs-based YOLO for object detection[J]. arXiv preprint arXiv:2406.05835, 2024.
[4] Glorioso, Paolo and Anthony, Quentin and Tokpanov, Yury and Whittington, James and Pilault, Jonathan and Ibrahim, Adam and Millidge, Beren. Zamba: A compact 7b ssm hybrid model[J]. arXiv preprint arXiv:2405.16712, 2024.
[5] Lieber, Opher and Lenz, Barak and Bata, Hofit and Cohen, Gal and Osin, Jhonathan and Dalmedigos, Itay and Safahi, Erez and Meirom, Shaked and Belinkov, Yonatan and Shalev-Shwartz, Shai and others. Jamba: A hybrid transformer-mamba language model[J]. arXiv preprint arXiv:2403.19887, 2024.
[6] Sharma, Harsh and Pfromm, Lukas and Topaloglu, Rasit Onur and Doppa, Janardhan Rao and Ogras, Umit Y and Kalyanraman, Ananth and Pande, Partha Pratim. Florets for chiplets: Data flow-aware high-performance and energy-efficient network-on-interposer for CNN inference tasks[J]. ACM Transactions on Embedded Computing Systems, 2023, 22(5s): 1-21.
[7] Krishnan, Gokul and Mandal, Sumit K and Pannala, Manvitha and Chakrabarti, Chaitali and Seo, Jae-Sun and Ogras, Umit Y and Cao, Yu. SIAM: Chiplet-based scalable in-memory acceleration with mesh for deep neural networks[J]. ACM Transactions on Embedded Computing Systems (TECS), 2021, 20(5s): 1-24.